Friday, December 11, 2015
Thursday, November 5, 2015
Monday, October 19, 2015
A Statistical Argument for Not Being Nervous on First Dates
A few months ago I became single for the first time in four years. I went from studying online dating to being a datapoint myself [1]. This has made me think more urgently about questions I once considered only abstractly. Today I write about the connection between testing statistical hypotheses and testing romantic attraction.
Statisticians love to develop multiple ways of testing the same thing. If I want to decide whether two groups of people have significantly different IQs, I can run a t-test or a rank sum test or a bootstrap or a regression. You can argue about which of these is most appropriate, but I basically think that if the effect is really statistically significant and large enough to matter, it should emerge regardless of which test you use, as long as the test is reasonable and your sample isn’t tiny. An effect that appears when you use a parametric test but not a nonparametric test is probably not worth writing home about [2].
A similar lesson applies, I think, to first dates. When you’re attracted to someone, you overanalyze everything you say, spend extra time trying to look attractive, etc. But if your mutual attraction is really statistically significant and large enough to matter, it should emerge regardless of the exact circumstances of a single evening. If the shirt you wear can fundamentally alter whether someone is attracted to you, you probably shouldn’t be life partners.
You can argue against this by pointing out cases where a tiny detail does matter because it prevents you from having any future interactions: for example, you foolishly wear your XL Chess Team sweatshirt to the bar and your would be Lothario never bothers to approach you and thereby discover that you look much better with it off.
This is a risk. In statistical terms, a glance at across a bar doesn’t give you a lot of data and increases the probability you’ll make an incorrect decision. As a statistician, I prefer not to work with small datasets, and similarly, I’ve never liked romantic environments that give me very little data about a person. (Don’t get me started on Tinder. The only thing I can think when I see some stranger staring at me out of a phone is, “My errorbars are huge!” which makes it very hard to assess attraction.)
Even on a longer date, there’s some risk that a disaster at the beginning will ruin your subsequent interactions. If you start by asking “how’s your relationship with your mother?”, you’ve torpedoed your chance to have a truly intimate conversation about how she ran off to train monkeys.
Still, I’m sticking to the principle that if your romance-to-be is statistically robust, whether you wear makeup or the moon is full should make no more difference than whether you compute the Spearman or Pearson correlation. (And if your date asks you if you want to bootstrap, the answer is always, of course, yes.)
I think there’s even an argument for being deliberately unattractive to your date, on the grounds that if they still like you, they must really like you. Imagine a cliched rom-com disaster [3]: you vomit on your date. This isn’t sexy. On the other hand, someone who finds you attractive after that is much more likely to still find you attractive when you’re puking during pregnancy or chemotherapy [4]. This is somewhat analogous to using a statistical test that makes very weak assumptions (here's one example): if the test yields positive results, you can have high confidence they're real.
Please don’t send me angry emails when you take this post too seriously and the love of your life spurns you because you didn’t shower for a week before your date. But I’d welcome your thoughts in the comments or via email. (Also hit me up if you have ideas for statistical projects that I can only conduct while single.)
Notes:
[1] I recently received an email from a Stanford professor in a similar situation: his marriage broke up after 20 years, and he responded by writing a book about the connections between economics and dating.
[2] An economics friend points out a corollary to this principle: be suspicious of analyses that use really convoluted tests when it seems like simple ones should do, because that might indicate that the simple ones didn’t produce the results they’re reporting.
[3] 10 Things I Hate About You, 50 Shades of Grey, Mean Girls. What’s with this trope, and why are the pukers always female?
[4] You’re calling me crazy and I’m kind of kidding, but I’d also argue that the idea of testing one’s partner is a socially accepted one. (My scholarly attempt to do a lit review on this question -- I Googled “make them work for it” -- yielded this text. You’re welcome.) There are many bad reasons people are told to defer sleeping with someone, but a not-so-bad-one, from a probabilistic standpoint, is that someone who will wait might be more likely to really like you.
Friday, October 16, 2015
A Better Way to Conduct Sexual Assault Surveys
Shengwu Li and I argue in the Washington Post that universities who conduct sexual assault surveys often misunderstand the basic statistical goal: not to get as many students as possible to answer the survey, but to get an unbiased sample of reasonable size. We propose a method for doing this.
Saturday, October 10, 2015
Analysis of the Online Abortion Debate
Brian Clifton, Gilad Lotan and I published an analysis of the fierce online debate about abortion. We visualize the spread of the hashtags #ShoutYourAbortion and #ShoutYourAdoption, develop a method for classifying tweeters as pro-choice or pro-life, and show that we can often predict someone's stance with high accuracy -- without ever reading their profile or tweets. Here is Brian's beautiful visualization of the spread of the hashtag.

Monday, September 21, 2015
A Tool for Mapping Drunk Tweets and Police Shootings
How do we map the density of a set of events? For example, we might want to map locations of tweets supporting Bernie Sanders as opposed to Hillary Clinton or locations of housing evictions or locations of police shootings. I confronted this problem recently while writing a post for Quartz (which they split into two) about where people tweet more about wine and where they tweet more about beer. Here’s a finished map (you can see more in the Quartz posts); color shows the fraction of #beer or #wine tweets which are about #wine, with red denoting pro-#wine areas.

I built a tool which lets you make maps like this, and because I think this problem is often useful to solve and often solved badly, I provide some thoughts on how to make maps below. If you’re not interested in details, you should probably just look at the maps in the Quartz posts, but if you keep reading you’ll at least get to see me make a lot of bad maps.
One simple thing to do is just to make a state-by-state map where each state’s color corresponds to the density of events. This has a few problems. It requires us to map all the latitude, longitude pairs to their states, and if we want to look a country besides America, we need to adapt our method; more fundamentally, it’s not very high-resolution, and there are often interesting patterns at the sub-state level.
To get better resolution, people often just plot the exact latitude, longitude location of the tweets, so you get visualizations that look like this:
Which is pretty but not very useful (like your momma!) because it basically just shows us where the cities are. (I have lost track of the number of data analyses I have read that can be summarized as, “when you have more people, more things happen”).
What I think you usually want to do is plot the density of events relative to some background. For example, I don’t care about the absolute density of wine tweets, which will be heavily correlated with population density; I care about the fraction of beer/wine tweets which are wine tweets.
So one thing we can do is estimate the density of wine tweets, estimate the density of beer tweets and then plot the difference: densitywine - densitybeer. (We can estimate density using a method called, appropriately, kernel density estimation). Here’s what happens when we do that; red denotes areas with more wine, blue with more beer.
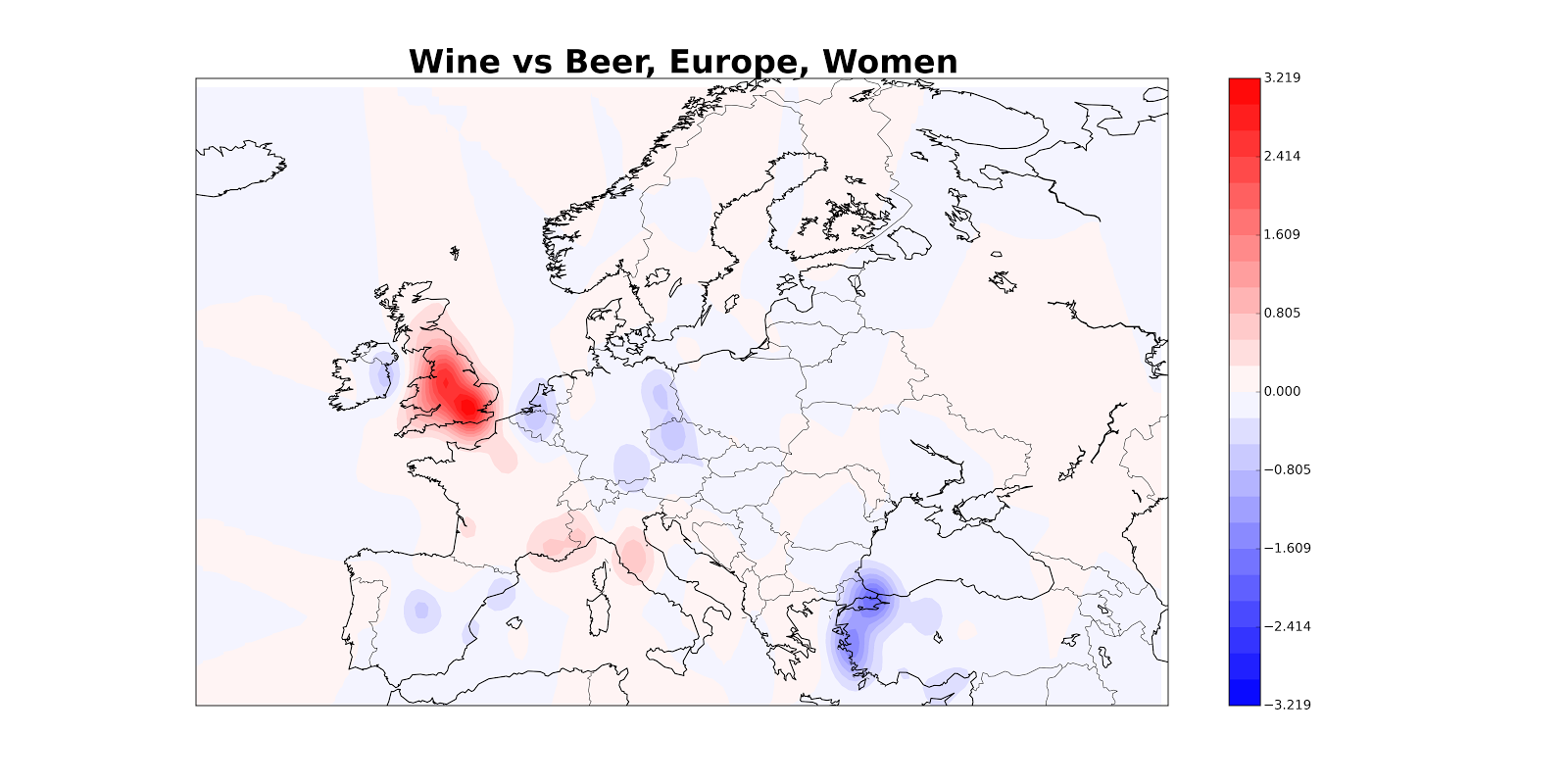
The problem is that the reddest areas aren’t necessarily the areas where 90% of people are tweeting about wine; they might also just be the areas with a ton of tweeters (which will also have larger differences between densitywine and densitybeer). So maybe we really want something like densitywine / (densitybeer + densitywine), which we can interpret as the fraction of tweets which are about wine. Here’s what that looks like.
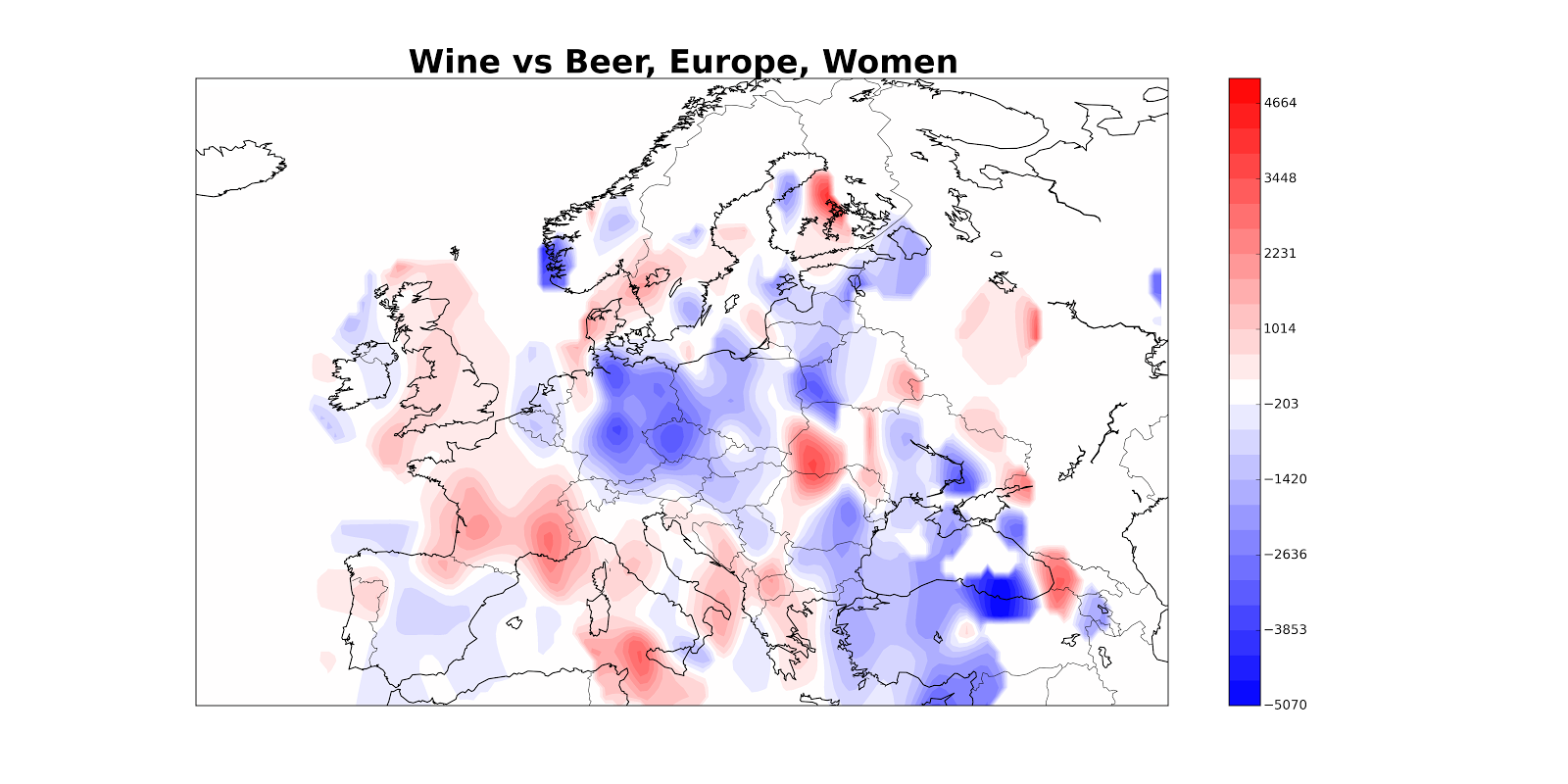
The problem, basically, is that the ratio of two things is unstable when the denominator gets small, which often happens. I tried various ways of getting around this but they were finicky.
So here’s an alternate solution: for every point which you want to color, look at the closest 10 beer/wine tweets and see how many of them are about beer. It seems like this will take a really long time if we have, say, 10,000 points and 50,000 tweets. Luckily, computer scientists have devised an efficient way of doing this which takes about two lines of code and a second to run (#MyFieldIsCoolerThanYourField) [1].
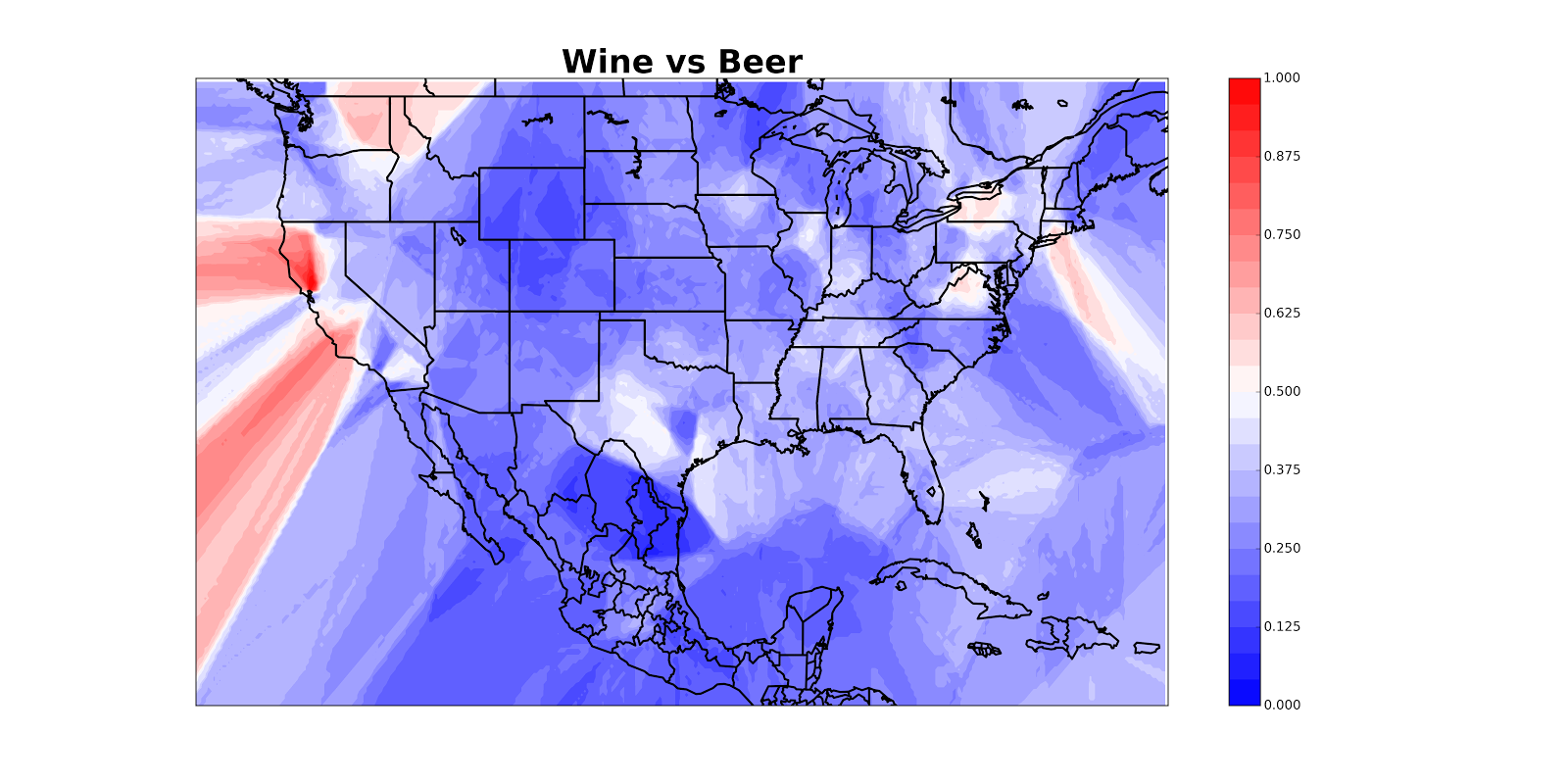
This doesn’t look so good because California appears to be hemorrhaging, but once we mask off the oceans we get a nice map:
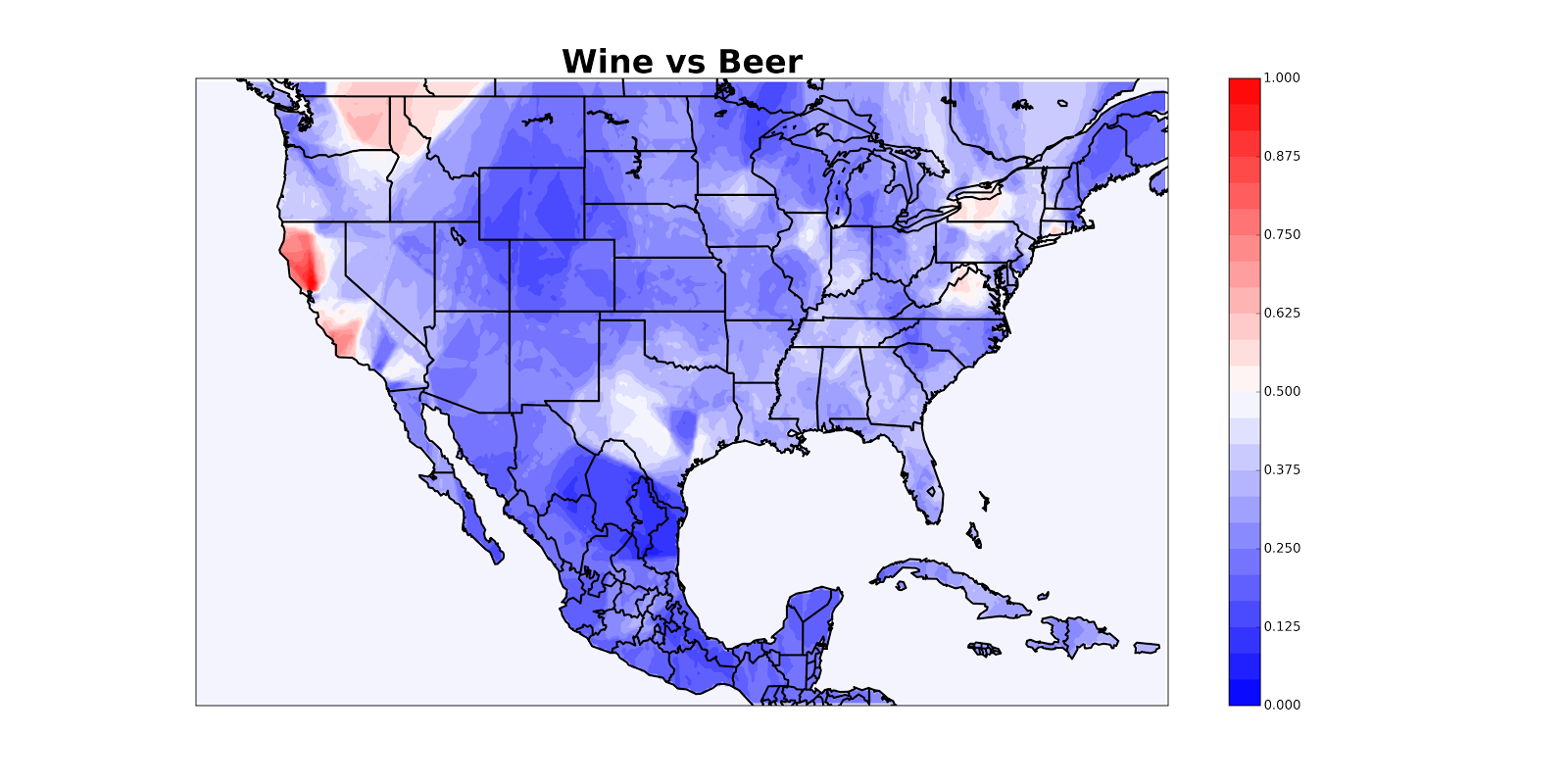
I’ve posted the code to make maps like these on GitHub so you can make maps of your own (and let me know if you find anything cool)! Keep in mind that the map will be less reliable in areas with little data. You can use it on any data (not just from Twitter) that has latitude and longitude. It requires knowledge of Python, so shoot me an email if you get stuck. If I get enough complaints from people who want to make maps but can’t use Python, I’ll just build a web tool.
Also, I am not a mapmaking expert, so feel free to tell me how I could’ve used CartoDB or whatever to do all this! (My problem with CartoDB is that the free version won’t keep data private and limits the size of your datasets to 50 MB. I’m not really a 50 MB kind of girl.)
Notes:
[1] We just train a k-nearest neighbors classifier and plot its classification surface. There’s also the question of how you choose the number of nearest neighbors to look at. If you choose too small a number, the map gets very splotchy:
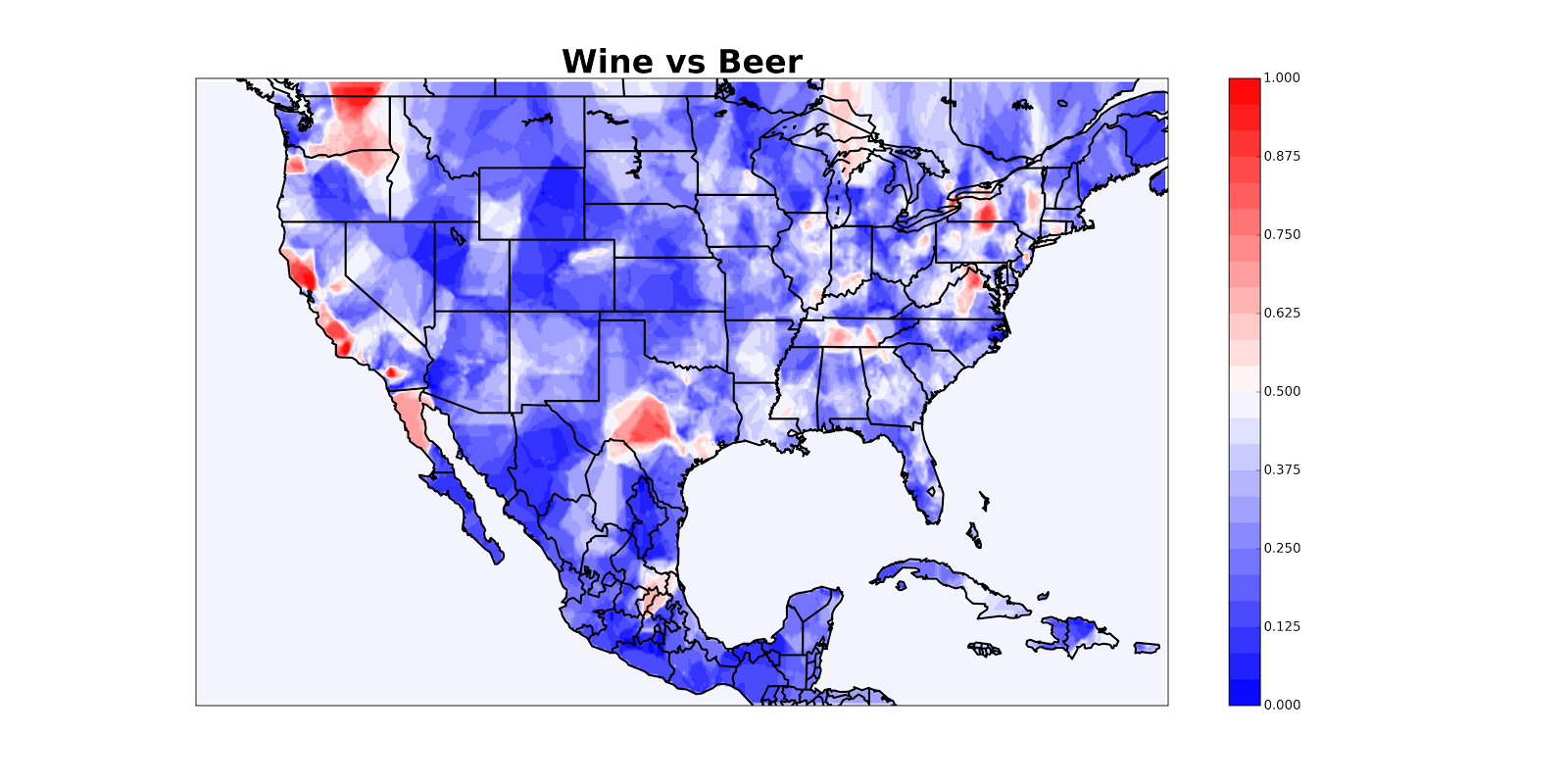
And if you choose too large a number, you lose real details. I’m not exactly sure how best to choose, so hit me up if you have thoughts. Do not tell me to use cross-validation. Seriously, we’re mapping drunk tweets here.
A final note: this tool obviously relies on you having latitude / longitude data. Many datasets are not in this form (eg, they might include addresses instead) and I have not found a great way to rapidly convert between addresses and latitudes / longitudes, because many APIs are rate limited. Let me know if you have a good solution to this problem.
Saturday, August 29, 2015
Friday, August 7, 2015
I Look Like an Engineer
This week tens of thousands of female engineers tweeted pictures of themselves and explanations of the work they do under the hashtag #ILookLikeAnEngineer. The movement made the front page of the New York Times, and so I decided to see what I could do with the tweets. Because this is a post about female engineers, I will describe the engineering steps in a little more detail:
- I used a program to scrape roughly 100,000 #ILookLikeAnEngineer tweets.
- From each tweet, I extracted any links to images, filtering out retweets and duplicate links.
- Using what Mark Zuckerberg in The Social Network would call “a little wget magic”, I downloaded all the pictures from the links. This gave me roughly 10,000 pictures (1.2 GB). Then I created a site so that drunken fraternity men could rate the attractiveness of the women...no, never mind.
- I programmatically cropped all 10,000 images into squares of uniform size.
- I wanted to see if I could create mosaics: compose a large image from tiled smaller images. There are websites which do this but I was pretty sure they would choke on 1.2 GB of pictures and not give me the freedom to experiment with parameters. The better solution was to write code to do it, and the lazier solution was to see if someone else had already done that, which they had. This allowed me to create mosaics using only one line of code, but I didn’t like the initial output so I added a bunch of my code to their code until it did what I wanted.
Here are the final results. From far away, the mosaics look like Seurat: for example, here is the woman who started it all.
{kind=link}

Zoom in and you get lost in the individual pictures.

Here are some high resolution versions (warning: the files are large; zoom in). Please feel free to use them, with attribution, to persuade women to become engineers or do other socially useful things. (Do me a favor and let me know about it!)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I was working on this while watching the Republican debate, and at some point I got so tired of hearing overconfident men pretend to know more than they did. (The line that did me in was Huckabee’s assertion that scientists agree personhood begins at conception because of a fetus’s “DNA schedule”. What the hell is a DNA schedule?) So I went home and wrote code. I’m often comforted by the fact that, however loud and annoying the person lecturing me may be, they cannot get inside my skull: the silent sanctity of those few inches of space, the infinite freedom to reflect and create, remain my own.
And yet. It’s naive to think that freedom of thought is enough. My work requires a computer, which I need economic freedom to buy. And Huckabee’s proposed restrictions of contraception and abortion will reduce women’s economic freedom. My work is funded by government science agencies which Huckabee wants to cut. So even code is cold comfort at the moment.
Apologies for the slightly bleak ending. If you have a custom image you’d like female-engineerified or higher resolution versions of these images, I’m happy to do that. If you are one of the women portrayed here and are uncomfortable having your face composed of many smaller women, let me know and I will take your picture down. And if you have ideas for cool things to do with this dataset or ways to improve the mosaics, please let me know! (Some pretty obvious improvements one could make are a) filtering out non-faces and b) filtering out duplicate images.)
Thursday, July 23, 2015
Advice and Sample Essays for Prospective Rhodes, Marshall, NSF, NDSEG, and Hertz Applicants
When applying for graduate scholarships, you have an advantage if you’re from a school that’s had many previous candidates: you can read decades of essays from successful applicants, be groomed by scholarship advisors, and so on. You’re also at an advantage if you happen to be good at networking, and can reach out to previous successful candidates.
Both these things seem unfair to me. In an attempt to level the playing field, in this post I’m providing two things: the essays I used to apply for scholarships and some tips. Obviously, I am not an expert and my experience is only one datapoint. This advice is specific to the scholarships named in the title, which I applied for and received; it may be applicable to other competitions as well. (I also applied for the Gates, which had a similar process, but withdrew my application when I decided to go to Oxford.) If you use the materials, please respect the fact that I am providing you with personal information for your benefit; do not plagiarize, redistribute or talk to me about my essays. If you have questions which are not answered here and which you think would be useful for many applicants to have answered, feel free to contact me and I will update this post if necessary! I am, unfortunately, probably not going to answer questions about specific applications.
Should I apply? I think the answer to this question varies by scholarship.
NSF, NDSEG, Hertz: these all give you funding to pursue a science PhD at a program of our choice. If you are applying to science grad schools, I would strongly recommend you apply if you have any chance of winning; they’re free money and prestige with no downside besides the time investment. To find out whether you would be a competitive applicant, I would a) read the criteria for the scholarship and b) talk to a professor in the sciences, your school’s scholarship office, or a previous applicant.
Marshall: funding for several years of study at an institution in the United Kingdom. Has a reputation for being more academic than the Rhodes; see this Wikipedia entry which I suspect is written by a Marshall Scholar. If you think you might conceivably be interested in studying in the UK and have a reasonably strong academic record (minimum undergraduate GPA is above 3.7), I would apply.
Rhodes: funding for several years of study at Oxford. Two things to understand (which I didn’t) when applying: a) if you win, you will be under strong pressure not to turn it down (unlike other scholarships, the Rhodes does not name alternates; I think this is silly, but that’s the way it is) and b) going to Oxford for a year or more can dramatically change your life. For example, I estimate that ⅔ of American Rhodes Scholars in long-distance relationships at the beginning of my year were not in relationships at the end. So try to actually imagine spending a year in Oxford; don’t just apply for the scholarship because it’s prestigious.
That said, I think the Rhodes is a wonderful experience, mostly because the other scholars are a diverse and passionate group and even if you’re somewhat antisocial like me you’ll probably make a lot of friends. (Update in the interest of balance: a 2014 Marshall Scholar tells me that the Marshall can also change your life and is well worth applying for.) Also, don’t be deterred from applying because:
- “the Rhodes is just for athletes” ~ this is no longer really true. I wrote on my resume that I did “long-distance hiking”, which was true but pretty lame.
- “the Rhodes isn’t for scientists” ~ silly for at least three reasons. i) there were lots of scientists in my year; ii) spending a year talking to non-scientists is arguably especially useful for scientists, because you’re probably going to spend the rest of your life surrounded by scientists; iii) many Rhodes scientists go on to do useful things precisely because they can communicate with non-scientists: see Leana Wen, Atul Gawande, Siddhartha Mukherjee, and Jonah Lehrer.
- “the Rhodes application involves a cocktail party” ~ it’s really not a big deal. There were no cocktails at mine.
Advice for all scholarships: if you’re not sure whether you have any chance, err on the side of applying. All scholarships are kind of a crapshoot, and it’s easy to get intimidated by profiles of the winners (I did).
Tips for essays:
a) start early. Some people start writing their Rhodes essays 6 months ahead of time (I started in July for the September deadline, but I also took ideas from writing I had done much earlier). Some candidates describe the essay-writing process as one of self-discovery: you decide what matters to you as you’re writing the essay. This takes time and multiple drafts.
b) most of the essays require you to both tell personal stories and detail your academic achievements. This combination made me uncomfortable (rereading my essays, I feel like a bit of an asshole) and you may feel the same way. It is okay to be honest about why you are an impressive candidate; just try not to sound too arrogant.
c) do not worry if you don’t have some inspiring personal story explaining why you care about what you study. Many successful candidates don’t. That said, if your academic and personal lives are entwined, by all means incorporate that. I would advise against including sad personal stories that aren’t actually deeply important to you, not just because it’s kind of a sleazy thing to do but also because it’s unlikely to be effective.
Tips for interviews:
The Rhodes, Marshall, and Hertz involve interviews (the Hertz has two rounds).
a) It is normal to be unable to answer interview questions. This happened to me in both the Rhodes and Hertz interviews. Admit it, don’t bullshit, tell them what you do know, and don’t panic. I know successful candidates who thought their interviews were disastrous.
b) The thing that prepared me best for interviews was doing college debate, which trained me to give a concise and structured answer and then defend it. A good way to prep for interviews is to have debaters read your application and ask you questions -- or, if you are lucky enough not to know any debaters, smart, obnoxious, argumentative people. Old scholarship applicants are also good at doing practice interviews, which I recommend doing -- contact your school’s scholarship office to see if they will arrange them.
c) Read old interview questions to get a sense of what you’ll be facing. I provide a complete list of my interview questions in the Rhodes and Marshall folders; here are some Hertz interview questions. For the Hertz interview, I might recommend Randall Munroe’s What If? which speculates about what would occur in a bunch of implausible physical scenarios; see if you can figure them out without reading his answers. (In my Hertz interview, I was asked what would happen if a car with a helium balloon tied to the floor suddenly stopped on the highway. Another candidate was asked to name every way he could use common kitchen implements to distinguish between salt and sugar.) Google is your friend for practice interview questions.
d) Be prepared to defend everything in your application. Candidates who claim they spoke a foreign language have been addressed in that language. I was asked to recite an equation from a paper I wrote. Reread your application before your interview, and don’t claim achievements you can’t defend.
e) Get the small stuff right. Show up really early. Wear a suit. If you’re flying in for the interview, it’s probably worth it to fly in a day early if you can.
f) Prepare for each interview specifically. The Rhodes and Marshall will require knowledge of current events. The Rhodes interviewers may ask you about Cecil Rhodes, and the Marshall interviewers may ask you about George Marshall and the United Kingdom. The Hertz interviewers may ask you basic science questions in fields you claim to know about (I was a physics major, so I reviewed my quantum / statistical mechanics and electromagnetism notes. I told them I hadn’t taken chemistry since 10th grade, so they left me alone about that). Research your interviewers (you will often know their names) so you can tailor your answers to their level of knowledge. Prior to my final round Hertz interview, I wrote up a short statistical analysis of previous Hertz candidates and presented it to my interviewers.
Longer-term tips:
The New York Times tells me that people start preparing to apply for these scholarships freshman year. (I also like that article because it makes Harvard sound evil.) That is definitely not always true; certainly no one sent me the memo (although maybe Stanford does for some people). That said, winning any of these scholarships will require you to have done things before your senior year -- and those things are worth doing anyway. Specifically:
a) Get to know your professors. This helps in two ways. First, all these scholarships require at least 3 letters of recommendation (the Rhodes requires 5 - 8). Letters carry a lot of weight, and they should be from people who know you reasonably well -- getting an A in someone’s class is probably not sufficient. (I had done research or one-on-one work for most people who wrote my Rhodes recommendations.) Second, most professors are way smarter than their students. If you want to meet dazzling people who will help you learn a lot and do cool things, professors are good people to talk to.
b) Do things that you’ll probably fail at but will offer a large reward if you succeed, as long as there’s no downside to failure besides time and ego. Examples: try taking classes for which you lack the prerequisites, as long as you can drop the class if you’re clearly unprepared. Send your writing to publications which are likely to reject it. Reach out to people who are too important to talk to you. Do academic research. Apply for awards. Etc. You will not win these scholarships simply by having a good GPA.
Hopefully this was at least somewhat helpful and not hopelessly generic. If you have successfully applied for these scholarships and would like to contribute tips or essays, please let me know!
Other resources I found useful: see Phillip Guo and DJ Strouse on science fellowships and Alex Lang on the NSF. I did not find that much useful writing on the Marshall or Rhodes, but try Googling. Your school’s scholarship office, your professors, and past winners or applicants are all worth reaching out to.
Update:
Thanks to Talmo Pereira, an NSF winner who offers the following resources:
"Really handy also were: UMissouri GRFP Essay Insights, Jennifer Wang's NSF links
And here are my application materials (2015): Research Plan - Personal Statement - Ratings Sheet"
Thanks also to a recent Marshall Scholar who wished to remain anonymous but who shared their interview questions; I have added them to the Dropbox folder with the requested caveat that "all interviews are different and this set of questions will not be representative of other experiences".
Thanks also to a recent Marshall Scholar who wished to remain anonymous but who shared their interview questions; I have added them to the Dropbox folder with the requested caveat that "all interviews are different and this set of questions will not be representative of other experiences".
Subscribe to:
Posts (Atom)